Adobe Research·Georgia Institute of Technology·* Core contributors·† Project lead
FLARE converts strong autoregressive (AR) hybrid-attention LLMs into diffusion LLMs with a single, low-cost training stage. One checkpoint then decodes two ways — AR-style speculative decoding (draft & verify) for quality, and diffusion-style parallel decoding for speed — staying close to its AR source while running far faster than other open diffusion LLMs.
A short overview — FLARE: one checkpoint, two ways to decode.
Abstract
One checkpoint, two ways to decode
Autoregressive (AR) LLMs are bottlenecked by sequential decoding. Two efficiency threads address this separately: hybrid attention backbones make each forward pass cheaper, while diffusion LLMs (dLLMs) cut the number of serial steps via parallel denoising. FLARE is a systematic conversion framework that combines both. It pairs a token-equal AR-and-diffusion objective with hardware-aware kernels and a unified inference stack, so one checkpoint supports both AR-style speculative decoding and diffusion-style parallel denoising. Starting from strong AR checkpoints with limited post-training data, FLARE is competitive with leading open-source dLLMs across scales and delivers consistent throughput gains in single-GPU concurrent serving — while our analysis shows that, once the clean/noisy objective and mask are correctly designed, transfer-data quality dominates the remaining gap in capability preservation.
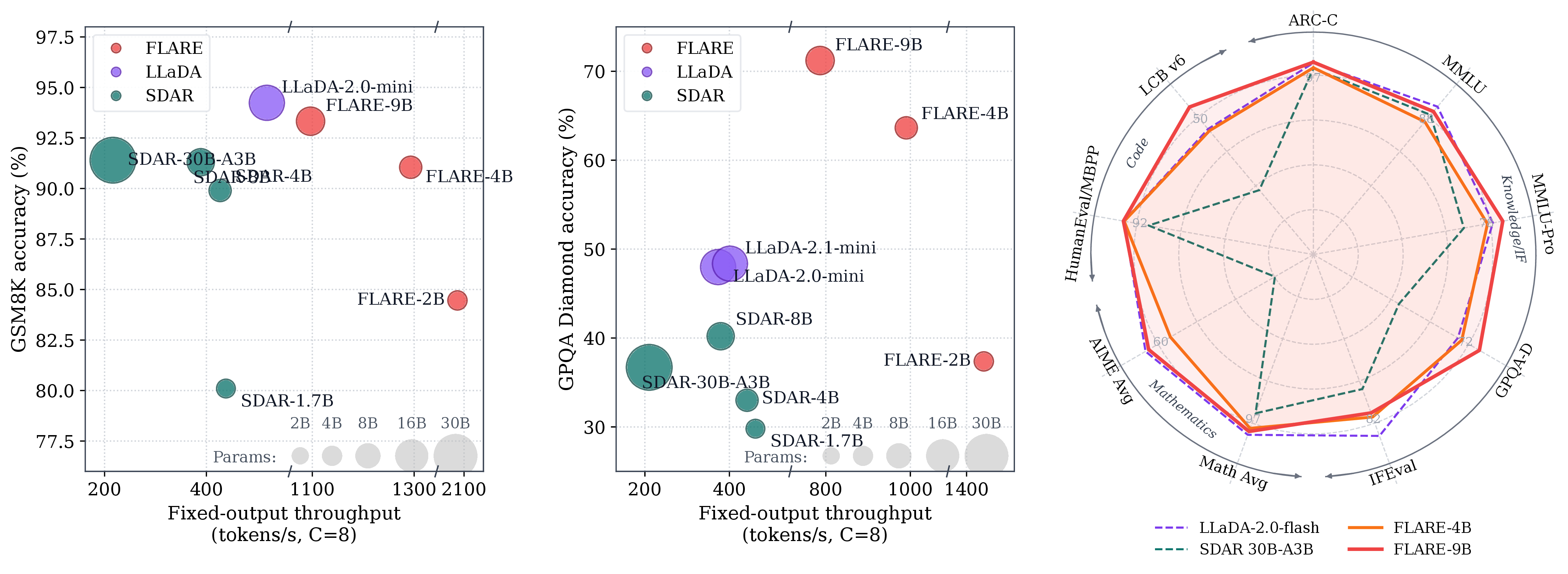
FLARE-2B / 4B / 9B are converted from Qwen3.5 hybrid-attention checkpoints in a single SFT stage (~10B tokens). Below: first capability against the AR source models and leading diffusion LLMs, then decoding throughput. FLARE numbers use AR-Trust speculative decoding unless noted.
Quality vs. throughput. FLARE positions as a state-of-the-art diffusion LLM — high sampling throughput paired with near-AR quality across the FLARE-2B / 4B / 9B scales.
Capability across scales — FLARE vs. its AR source (%)
Benchmark
FLARE-2B
FLARE-4B
FLARE-9B
Qwen3.5-2B
Qwen3.5-4B
Qwen3.5-9B
FLARE (AR-Trust)
AR source
Knowledge & Instruction Following
ARC-Challenge
85.07
93.52
96.33
92.15
96.33
97.70
MMLU
67.60
78.73
84.80
73.59
85.22
88.21
MMLU-Pro
53.57
71.14
77.39
59.53
77.88
81.39
GPQA-Diamond
37.37
63.64
71.21
62.12
80.30
80.30
IFEval
68.95
73.20
71.35
79.48
90.02
91.31
Math & Reasoning
GSM8K
84.46
91.05
93.33
77.63
89.16
89.16
MATH-500
84.40
94.20
95.20
72.20
95.40
96.60
AIME-24
31.11
58.89
63.33
8.89
63.33
65.56
AIME-25
26.67
43.33
54.44
12.22
48.89
60.00
Code
HumanEval
64.02
93.29
92.07
48.17
87.80
95.12
MBPP
68.09
89.11
91.05
53.31
82.49
89.11
LiveCodeBench v6
15.43
41.71
49.71
17.71
50.86
49.71
All values use AR-Trust speculative decoding. Under a ~10B-token conversion, FLARE-9B keeps up to 95–99% of its AR source on math/knowledge (e.g. MATH-500 95.20 vs. 96.60, AIME-24 63.33 vs. 65.56, MMLU-Pro 77.39 vs. 81.39) and even exceeds the source on MBPP (91.05 vs. 89.11); a residual gap remains on instruction-following and some code. (The paper's "potentially under-reported" star markers on a few Qwen3.5 values are omitted here.)
FLARE-9B vs. leading diffusion LLMs (%)
Benchmark
FLARE-9B
LLaDA-2.1-flash
SDAR-30B-A3B
Mercury-2
9B
100B-A5B
30B-A3B
commercial
GPQA-Diamond
71.21
66.67
36.7
73.00
MMLU-Pro
77.39
75.31
61.5
—
MATH-500
95.20
—
77.8
81.00
AIME-24
63.33
—
16.7
51.10
MBPP
91.05
88.29
71.6
—
LiveCodeBench v6
49.71
44.05
21.7
67.30
IFEval
71.35
83.36
60.6
—
FLARE-9B matches or beats the 100B-A5B LLaDA-2.1-flash on these shared benchmarks at roughly 1/10 the parameters, and beats the commercial Mercury-2 on math (MATH-500 +14.2, AIME-24 +12.2) — Mercury-2 keeps an edge on LiveCodeBench. Dashes = not reported by that system. See the paper for the full baseline set (LLaDA-2.0, SDAR-1.7B/4B/8B).
Two modes, one checkpoint. FLARE-9B's Diffusion-Trust path stays close to AR-Trust on math and knowledge (MATH-500 93.60 vs. 95.20, MMLU-Pro 74.73 vs. 77.39) but trails on long, strictly-structured code (LiveCodeBench v6 5.71 vs. 49.71, MBPP 82.10 vs. 91.05) — the same checkpoint simply switches its sampling path.
Decoding throughput — GSM8K, tokens / second
FLARE-2B2087
FLARE-4B1293
FLARE-9B1097
LLaDA-2.1-mini963
SDAR-1.7B438
High-concurrency throughput. Tokens/s at concurrency C=8 on a single A100-80GB (bf16, SGLang, max_new_tokens=2048). FLARE-2B is 2.2× LLaDA-2.1-mini and 4.8× SDAR-1.7B on GSM8K.
Model
GSM8K
HumanEval
GPQA-Diamond
FLARE-2B
2087.0
1763.9
1440.8
FLARE-4B
1293.2
1178.9
990.4
FLARE-9B
1096.5
1007.1
786.5
LLaDA-2.1-mini
963.0
1646.5
401.2
SDAR-1.7B
438.3
427.0
461.5
tokens/s at C=8, 1× A100-80GB. The gain is largest at high concurrency, where per-step overhead dominates and FLARE's fused hybrid kernels keep the recurrent state off the critical path.
§ 2 — Method
How FLARE turns an AR model into a diffusion LLM
FLARE starts from a strong AR hybrid-attention backbone (softmax + linear/recurrent attention, e.g. Gated DeltaNet in Qwen3.5) and teaches it to also denoise — with one objective that shows the model two views of every block in a single forward pass. The same weights can then generate left-to-right or fill in a whole block in parallel.
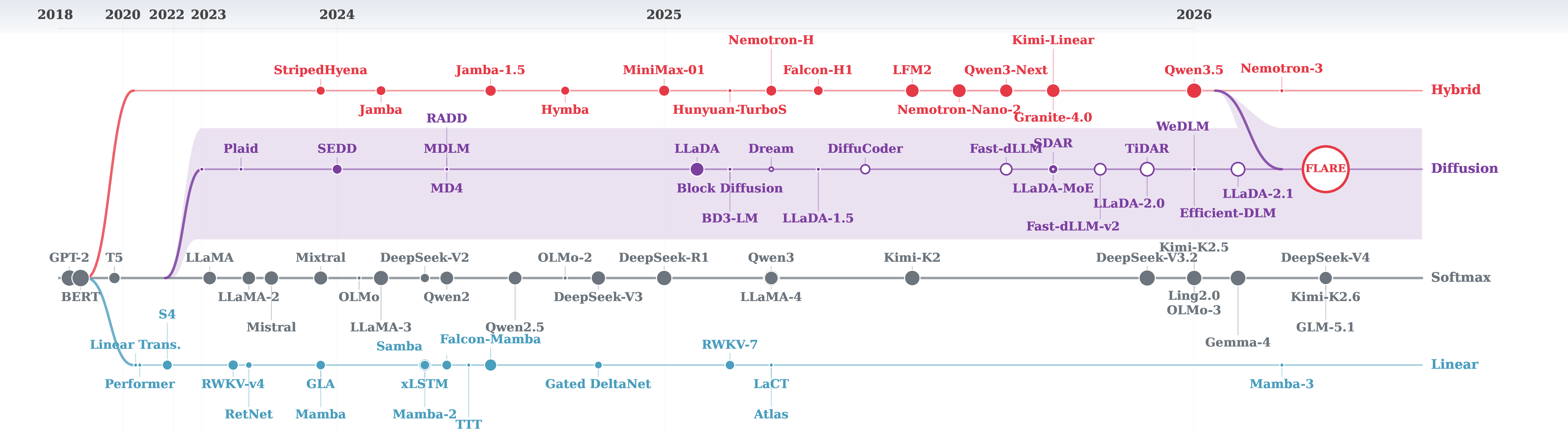
Where FLARE sits. The confluence of two efficiency threads — algorithmic efficiency from diffusion (fewer serial steps) and architectural efficiency from hybrid attention (cheaper forward passes).
Training — two views of every block, one forward pass
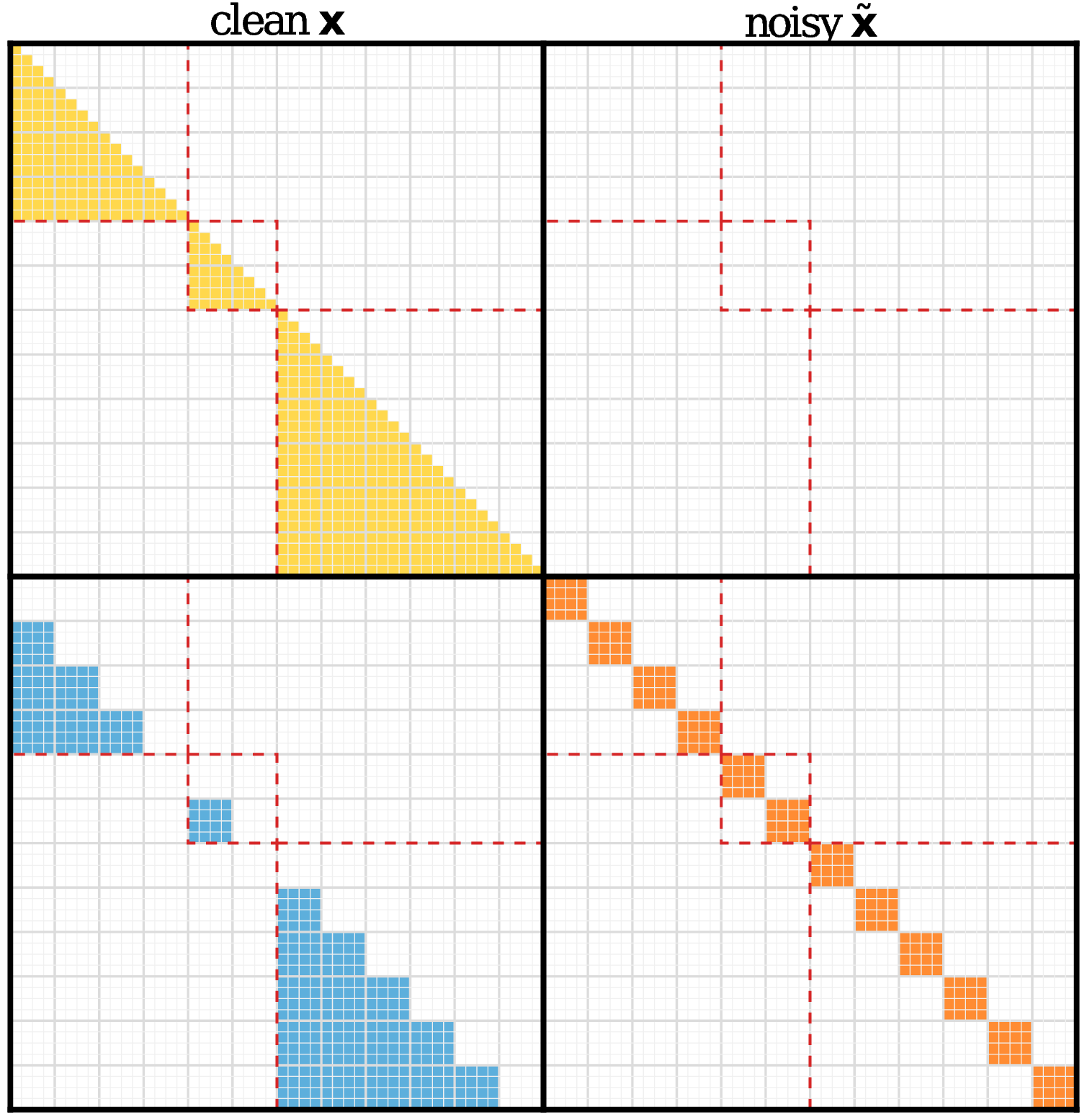
The response is split into blocks. In a single pass the model sees each block twice: a clean, left-to-right view (the usual next-token objective) and a noisy, masked view it must denoise (the diffusion objective). Because the masked and unmasked tokens partition the block, every token contributes exactly one AR signal and one diffusion signal at unit weight — keeping the two balanced and giving one checkpoint both causal generation and block-parallel denoising.
The packed clean/noisy attention mask. Causal clean (yellow), block-bidirectional noisy (orange), noisy→clean visibility (blue), and document boundaries (red) — realizing the objective above in one packed forward pass, with no cross-document leakage.
In softmax layers this is a visibility matrix; in linear-attention layers it becomes a recurrent-state schedule — the kernel challenge addressed in Efficiency.
Inference — one checkpoint, two decoding modes
AR Trust
Speculative decoding
The noisy stream proposes a block of draft tokens that the clean stream then verifies left-to-right — classic draft-and-verify speculative decoding. Under exact verification it matches FLARE's own AR distribution, so quality is preserved; speed scales with the acceptance rate.
Diff Trust
Parallel denoising
Commit block-denoised tokens in parallel by confidence — fewer serial steps, higher throughput. Speed scales with the block-to-step ratio.
The two decoding paths, step by step.Diffusion-Trust denoises a masked block in parallel; AR-Trust drafts a block and verifies it left-to-right — accept · reject · resample · discard. One checkpoint, two paths.
§ 3 — Analysis
What makes the transfer work
A controlled study on a Qwen3-1.7B seed (fixed ~10B-token budget, 12-benchmark suite) isolates the ingredients of AR→dLLM transfer. Three findings, in the order they matter.
Finding 1 — the primary lever
An AR-aligned clean stream preserves capability
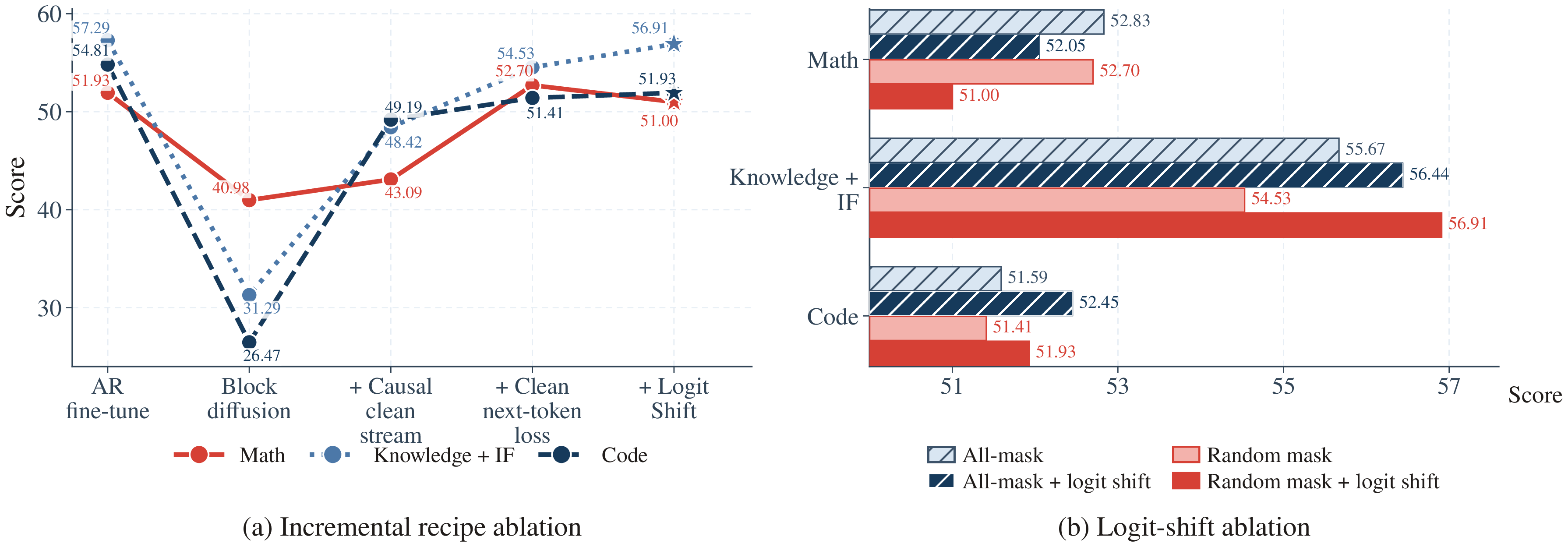
Starting from AR fine-tuning, switching to a pure block-diffusion objective degrades every capability group — averaging −21.8 pts, with the heaviest drops on Code and Knowledge + IF. The largest single-step recovery comes from restoring a token-causal AR clean stream (+14.0 pts on average), which alone closes most of that gap. Adding a clean-stream next-token loss pulls Math back to the AR-fine-tuning level, and logit shift saturates it.
Cumulative recipe step
Avg. capability Δ
Pure block-diffusion
−21.8
+ token-causal AR clean stream
+14.0
+ clean next-token loss
recovers Math
+ logit shift
near-saturated
Incremental recipe ablation (Qwen3-1.7B, Mix 1). Capability collapses under pure block diffusion and is recovered step-by-step — the causal clean stream is the largest single lever.
Finding 2 — the ceiling
Transfer-data quality sets the attainable quality
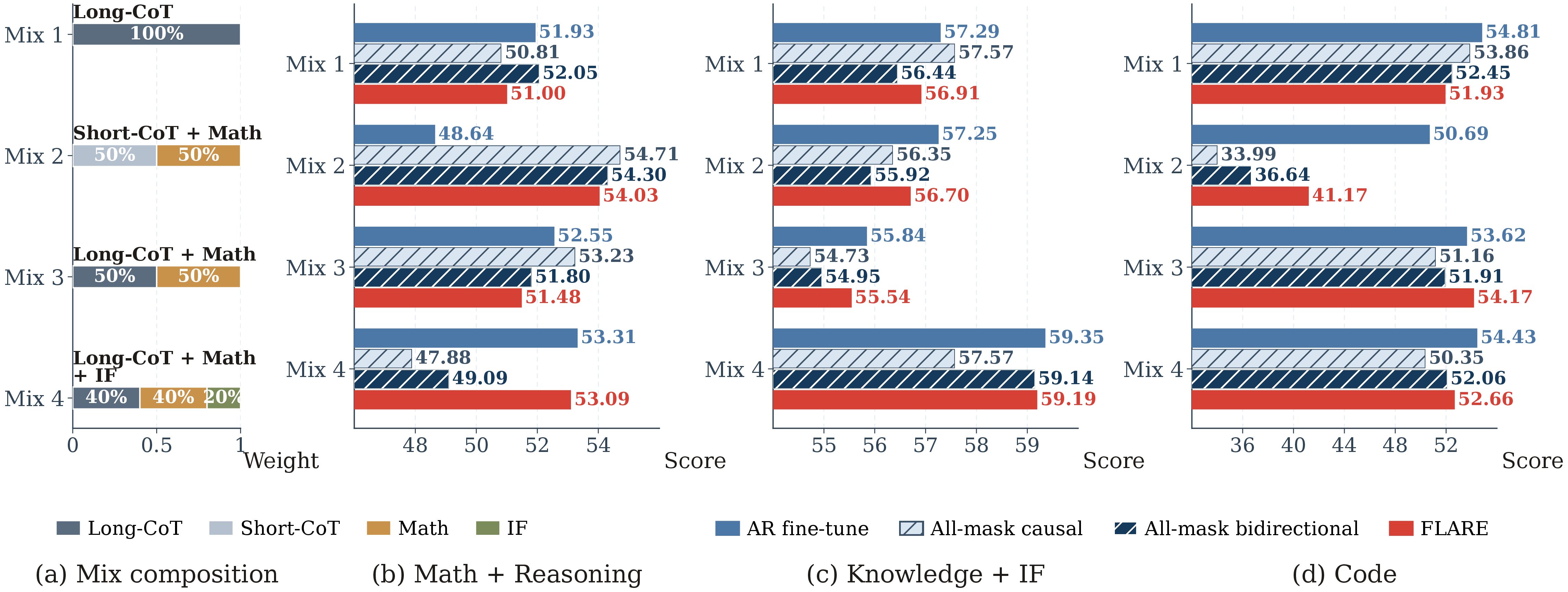
Once the objective is aligned, the converted dLLM tracks its AR-SFT counterpart under the same data mix — so cheap AR fine-tuning is a faithful proxy for screening data mixes before the more expensive dLLM conversion. No single data change is uniformly good: a math-heavy mix helps reasoning but hurts code, while adding instruction-following data gives the best balanced result (the mix FLARE ships with).
Transfer-data composition study (Qwen3-1.7B). Converted dLLMs largely track their AR fine-tuning counterparts under the same mix; the data mix — not the algorithm — sets the attainable quality per capability group.
At fixed AR-aligned clean supervision, all-masked vs. random noisy views give comparable accuracy — so noisy-mask sampling is not a primary driver of benchmark scores. Its real role is decoding compatibility: random masking trains the noisy stream as a genuine denoising path and preserves Diffusion-Trust decoding, while logit shift aligns the block-diffusion logits with inference-time token positions.
§ 4 — Efficiency
Hardware-efficient two-stream training
The clean/noisy mask is a simple visibility matrix in softmax layers, but in linear-attention (Gated DeltaNet) layers, visibility lives in the recurrent state itself: each noisy block must be seeded from the correct clean boundary state, see its own tokens, and never leak into other blocks or packed documents. The mask therefore becomes a state-scheduling problem — and there are two ways to solve it.
I
The simple way (memory-bound)
Compute the clean stream first, store every block-boundary state in HBM, then replay each noisy block from it. It is correct and reuses standard kernels — but the stored states scale with the number of blocks and blow up memory at the small block sizes diffusion needs.
II
FLARE's fused kernel
Keep only a few strided checkpoints, rebuild each boundary state in registers on the fly, consume the noisy block immediately, and fuse the convolution branch into one pass — so no per-block states are ever written out.
The fused kernel makes small blocks feasible
Total latency (ms, lower is better)
Simple kernel135.10
FLARE fused37.69
Peak memory (GiB, lower is better)
Simple kernel18.14
FLARE fused0.45
Kernel microbenchmark (Gated Delta Rule, block size B=1). FLARE's fused kernel cuts latency 3.6× (135.10→37.69 ms) and peak memory 40× (18.14→0.45 GiB) — making the small-block regime diffusion needs (FLARE uses B=4) feasible at all; the simple kernel runs out of memory there.
End-to-end training utilization
Unoptimized13.80%
+ Fused state kernel17.93%
+ Larger local batch21.40%
+ Fused conv24.81%
Pure-AR reference24.04%
Training MFU (FLARE-2B, B=4, 8×A100-80GB). The kernel stack lifts model-FLOPs-utilization to 24.81%, the same as the pure-AR Qwen3.5-2B reference (24.04%) on identical hardware — i.e. the fused kernels add no utilization penalty. Utilization is not cost, though: two-stream supervision sees each example as both a clean and a noisy view, so it processes ~2× the tokens of single-stream AR. Matching MFU means the GPU is kept just as busy — not that conversion is as cheap as AR per unique token.
§ 5 — Takeaways
What we learned
01
Clean-stream alignment preserves capability; data quality sets the ceiling.
An AR-aligned clean stream is the single biggest lever for capability-preserving conversion (+14.0 pts); once it is in place, transfer-data quality dominates the remaining gap, and dLLM quality tracks cheap AR-SFT.
02
One checkpoint, two decoding regimes.
A token-balanced clean/noisy objective yields a single model that serves both AR-Trust speculative (draft-and-verify) decoding and Diffusion-Trust parallel denoising — unified in one SGLang-based stack.
03
Fused kernels keep the GPU as busy as AR training.
Realizing diffusion visibility as a recurrent-state schedule with fused kernels runs at the same model-FLOPs-utilization as pure AR (24.81% vs. 24.04%) and cuts small-block kernel latency 3.6× and memory 40× — so the kernels add no utilization penalty; the inherent ~2× two-stream work is the only remaining cost.
04
Small budget, competitive quality, real speedups.
From strong AR checkpoints under ~10B transfer tokens, FLARE matches or beats much larger open dLLMs and retains most of its AR source, while delivering up to 4.8× throughput in single-GPU concurrent serving.
Read the paper & try FLARE
FLARE-2B / 4B / 9B convert strong AR hybrid-attention checkpoints into diffusion LLMs that decode in parallel. Code and model releases coming soon.
@article{zhu2026flare,
title = {FLARE: Diffusion for Hybrid Language Model},
author = {Zhu, Yuchen and Shi, Jing and Ge, Chongjian and Tan, Hao and
Xu, Yiran and Zhu, Wanrong and Kuen, Jason and Goswami, Koustava and
Jain, Rajiv and Chen, Yongxin and Tao, Molei and Gu, Jiuxiang},
journal = {arXiv preprint arXiv:2606.01774},
year = {2026}
}